
For example, imagine that a catering company uses the
following data to decide how many napkins to provide for a dinner party,
based on the number of people attending.
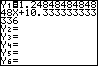
| No. of People | No. of Napkins |
| 10
20 30 40 50 60 70 80 90 100 |
23
35 48 60 73 85 98 110 123 135 |
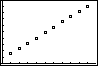
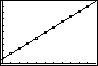
By now it should be quite easy for you to enter this data into your calculator, plot it to see that it is linear, perform a regression to find the equation for the best-fit line, enter that equation into the calculator, and graph it on top of the data:
But what does all this mean? To understand that, you have to understand the equation for a line and the significance of the slope and the intercept for any given data set.
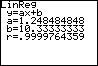
In this case, with napkins on the y-axis and people on the x-axis, the slope (a=1.25 napkins/person) represents the average number of napkins each person will need. For this data, a slope of 1.25 indicates that each person gets about one and a quarter napkins. What this really means is that each person gets their own, with one extra for every four people. (Perhaps one in four people is expected to spill something.)
The intercept (10 napkins) represents extra napkins which you should bring in addition to the 1.25 per person.
So the linear equation
can be "translated" into the statement
|
|
Again, the important thing to remember is that the meaning
of the constants from the regression equation depends entirely on the meanings
of the numbers in the original data set.
 |
 |